隱私計算說明介紹 (上)
| 01 隱私計算技術的起源 假設有兩個百萬富翁,他們都想知道誰更富有,但他們都想保護好自己的隱私, 都不願意讓對方或者任何第三方知道自己真正擁有多少財富。 那麼,如何在保護好雙方隱私的情況下,計算出誰更有錢呢? 這是2000年圖靈獎得主姚期智院士在1982年提出的“百萬富翁”問題。 這個燒腦的問題涉及這樣一個矛盾,如果想比較兩人誰更富有, 兩人似乎就必須公佈自己的真實財產數據。但是,兩個人又都希望保護自己的隱私, 不願讓對方或者任何第三方知道自己的財富。在普通人看來,這幾乎是一個無解的悖論。 然而在專業學者眼裡,這是一個加密學問題,可以表述為 “一組互不信任的參與方在需要保護隱私信息以及沒有可信第三方的前提下進行協同計算的問題”。 這也被稱為“多方安全計算”(Secure Multiparty Computation,SMC)問題。 姚期智院士在提出“多方安全計算”概念的同時, 也提出了自己的解決方案——混淆電路(Garbled Circuit)。 隨著多方安全計算問題的提出,投入到多方安全計算研究的學者越來越多。 除了混淆電路之外,秘密共享)、同態加密等技術也開始被用來解決多方安全計算問題, 隱私計算技術也逐步發展了起來。 |
| 02 隱私計算的概念 多方安全計算在20世紀80年代初提出的時候, 還只是作為一種亟待可行性驗證的技術理論, 而後計算機算力不斷提高,移動互聯網、 雲計算和大數據等技術快速發展, 催生了眾多新的服務模式和應用。 這些服務和應用一方面為用戶提供精準、個性化的服務, 給人們的生活帶來了極大便利;另一方面又採集了大量用戶的信息, 而所採集的信息中往往含有大量包括病史、收入、身份、 興趣及位置等在內的敏感信息,對這些信息的收集、共享、發布、 分析與利用等操作會直接或間接地洩露用戶隱私,給用戶帶來極大的威脅和困擾。 個人隱私保護成為人們廣泛關注的焦點, 人們也都認識到隱私信息是大數據的重要組成部分, 而隱私保護關乎個人、企業乃至國家的利益。 針對隱私保護問題,學術界開展了大量的研究工作, 包括多方安全計算技術在內的隱私保護技術在逐步完善發展中得以應用。 然而,隱私缺乏定量化的定義,隱私保護的效果、 隱私洩露的利益損失以及隱私保護方案融合的複雜性三者缺乏系統的計算模型, 這就使得隱私信息在不同系統和不同用戶間的共享、 交換和分析過程中難以被準確刻畫和量化, 阻礙了各類計算和信息服務系統對隱私進行有效、統一的評價。 針對這一問題,2016年, 中國科學院信息工程研究所研究員李鳳華等對隱私計算在概念上進行了界定: 隱私計算是面向隱私信息全生命週期保護的計算理論和方法, 具體是指在處理視頻、音頻、圖像、圖形、文字、數值、 泛在網絡行為信息流等信息時,對所涉及的隱私信息進行描述、度量、評價和融合等操作, 形成一套符號化、公式化且具有量化評價標準的隱私計算理論、 算法及應用技術,支持多系統融合的隱私信息保護。 隱私計算涵蓋信息所有者、蒐集者、發布者和使用者在信息採集、存儲、處理、發布(含交換)、 銷毀等全生命週期中的所有計算操作,是隱私信息的所有權、 管理權和使用權分離時隱私描述、度量、保護、效果評估、延伸控制、 隱私洩露收益損失比、隱私分析複雜性等方面的可計算模型與公理化系統。 同時,中國信通院根據數據的生命週期,將隱私計算技術分為數據存儲、 數據傳輸、數據計算過程、數據計算結果4個方面,每個方面都涉及不同的技術, 如圖1-1所示。數據存儲和數據傳輸技術相對成熟,讀者也可能應用過相關技術。 |
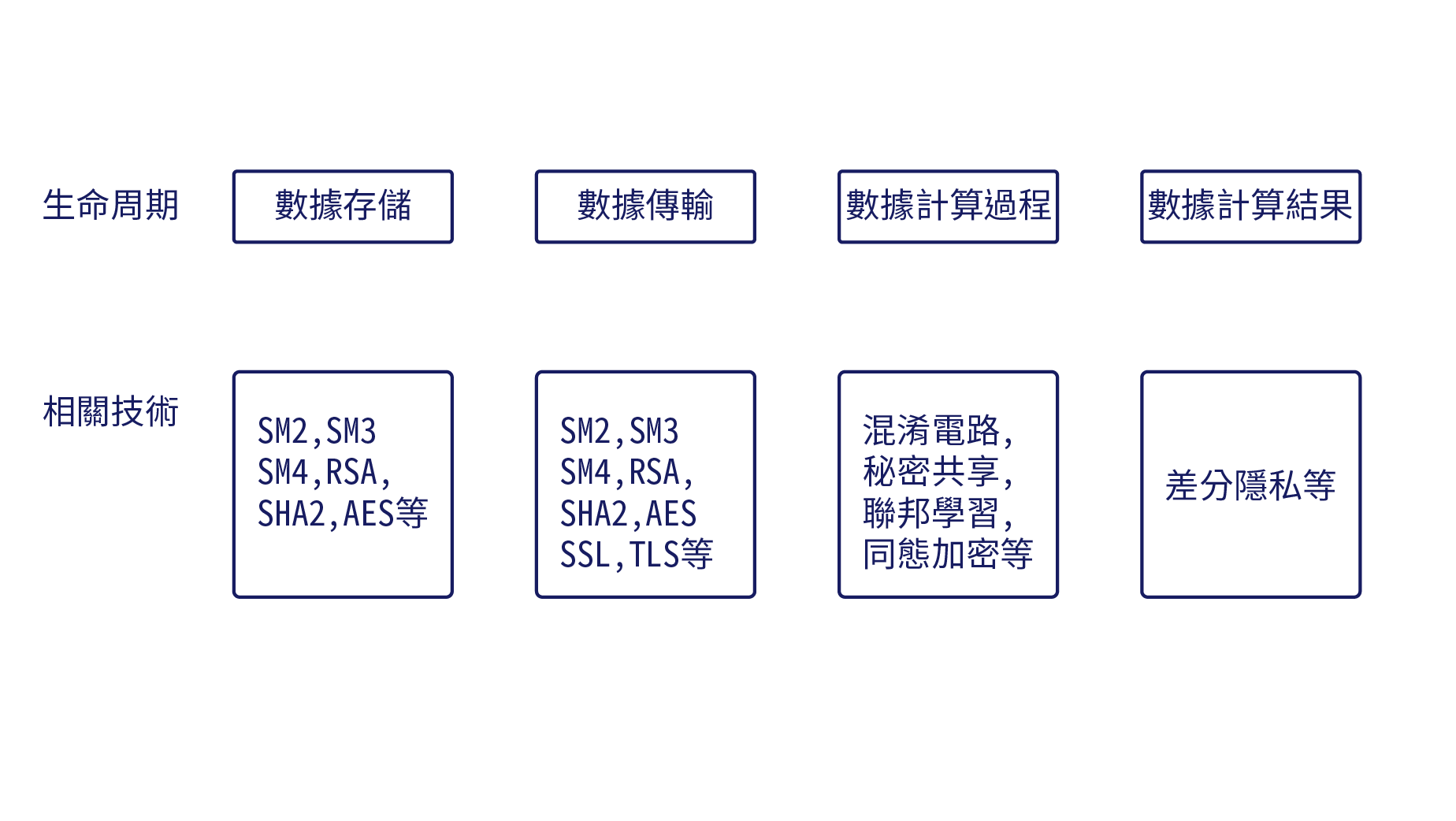 圖1-1 根據生命週期劃分的隱私計算技術 圖1-1 根據生命週期劃分的隱私計算技術 |
| 根據數據生命週期,我們可以將隱私計算的參與方分為輸入方、 計算方和結果使用方三個角色,如圖1-2所示。 在一般的隱私計算應用中,至少有兩個參與方, 部分參與方可以同時扮演兩個或兩個以上的角色。 計算方進行隱私計算時需要注意“輸入隱私”和“輸出隱私”。 輸入隱私是指參與方不能在非授權狀態下獲取或者解析出原始輸入數據以及中間計算結果, 輸出隱私是指參與方不能從輸出結果反推出敏感信息。 |
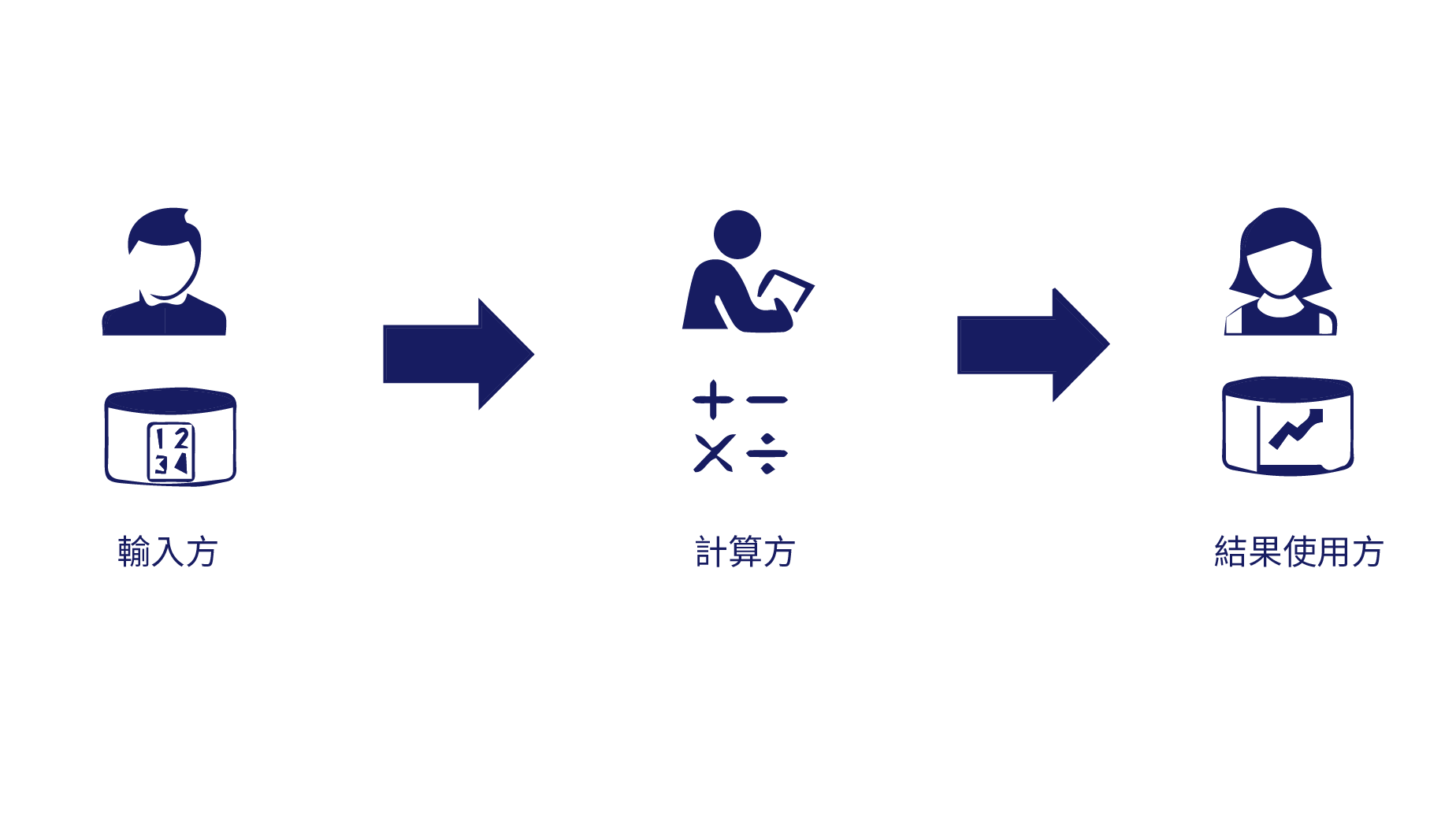 圖1-2 隱私計算參與方的三種角色 圖1-2 隱私計算參與方的三種角色 |
| 聯合國全球大數據工作組將隱私保護計算技術定義為在處理和分析數據的過程中能保持數據的加密狀態、 確保數據不會被洩露、無法被計算方以及其他非授權方獲取的技術。 與之基本同義的一個概念是“隱私增強計算技術”, 通常可換用。本文統一使用中文簡稱“隱私計算技術”。 |
若您希望得知更多資訊或有其他需求 請至 線上服務 留言 我們會盡快與您聯繫 也可從 聯絡我們 取得聯絡方式 |